
Welcome to Tonic.ai

Introducing Tonic.ai — Intelligent Synthetic Data Generation
How it all began
It was the best of times, it was the worst of times, it was the age of wisdom, it was the age of foolishness—it was 2am, and several business development engineers were sitting on-site in an otherwise empty building trying to debug some failing code. They had a large, brilliant development team in Palo Alto eager to help them, but they had no way to send the developers the data that was causing all the problems. The data was confidential client data containing a myriad of PII (SSNs, phone numbers, salary info, etc). In case it wasn’t already clear, I was one of those unlucky onsite engineers. As a Palantir analytics team, we were tasked with analyzing the mortgage portfolio at a large bank. It was right after the housing crisis, so the work needed to be done yesterday, well, 2 years before yesterday, if I’m honest.
I saw versions of this problem in other roles at other organizations, and when my co-founders and I started brainstorming, the pain caused by data silos and restrictions on data portability was top of mind. We had solved the problem several times by manually creating synthetic data (data that possesses nearly identical structural, behavioral, and statistical properties to the protected data, but without any secure info in it). It was painful and laborious, taking weeks of a talented engineers’ time, not to mention the ongoing maintenance cost.
Each time we’d been shocked to find there wasn’t any strong tooling available to help create synthetic data.
What we did about it
To rescue these past versions of ourselves, we started a company with the goal of automating the creation of synthetic data. But our mission has become much larger than helping out the business development engineers who filled our shoes. A broad range of company activities, from new product development to sales demo creation to model generation, require access to sensitive data, yet providing large teams with unfettered access not only poses security risks, but leads to painful overhead for IT admins and users alike.
The challenges of replicating a data environment manifest in unexpected ways and deliver ongoing hits to productivity. The end result is often cumbersome VM environments to control access, large expensive teams only able to be productive while onsite, and/or draconian monitoring of large swaths of employees who have access to sensitive data. It can also lead to uncompelling sales demos or data scientists spending 80% of their time cleaning up or acquiring data.
If this sounds like something that plagues your organization, we’d love to chat.
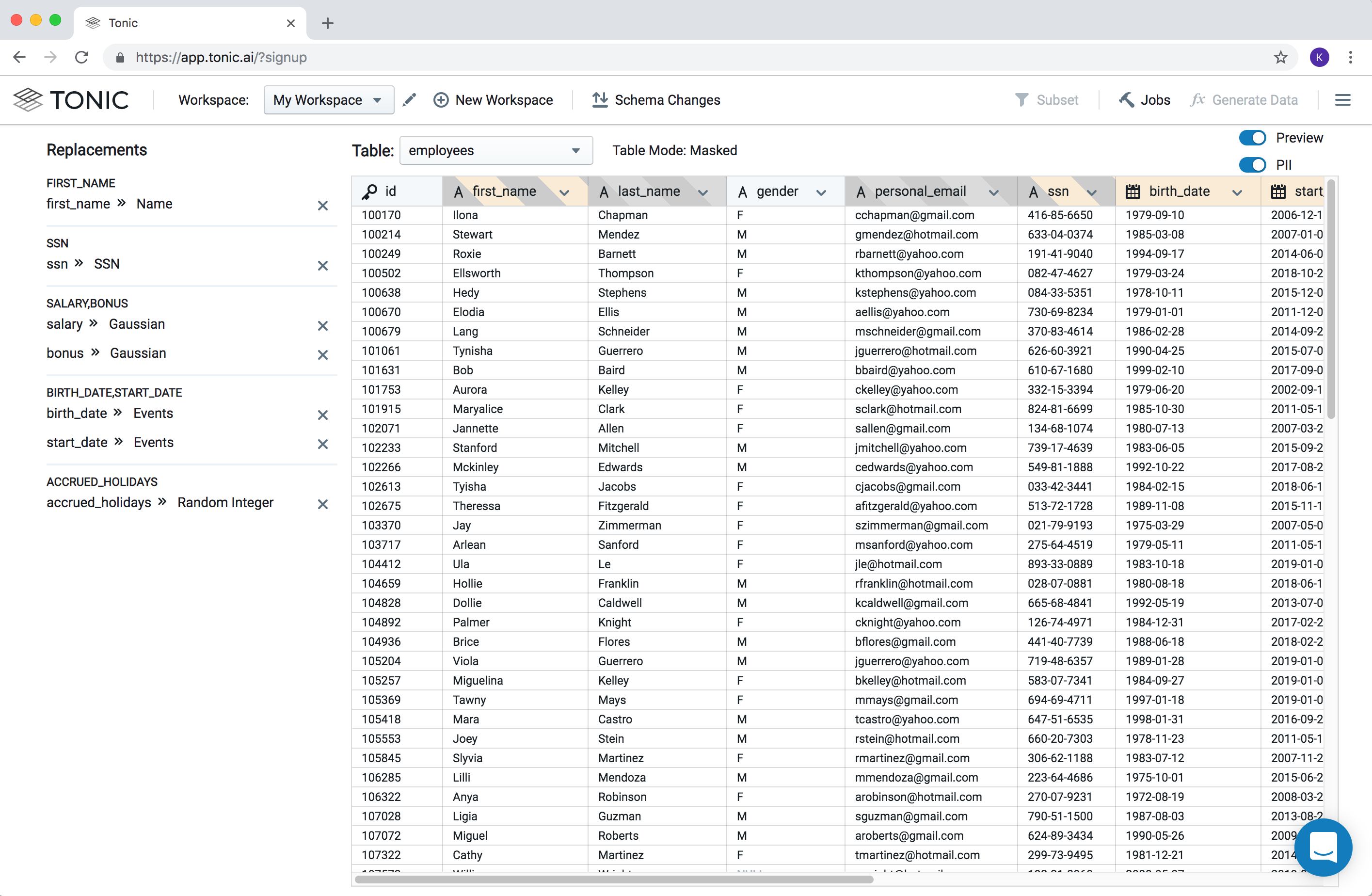
How it works—A secure, shareable “fingerprint”
By combining basic database cloning techniques with machine learning, Tonic creates a data fingerprint for each internal datastore that encodes key info necessary to replicate the source. After detecting constraints, statistical correlations, distributions and structure, Tonic provides an intuitive UI for verification and final edits. Ultimately, the new data can be used to hydrate any source, on-prem or in the cloud.
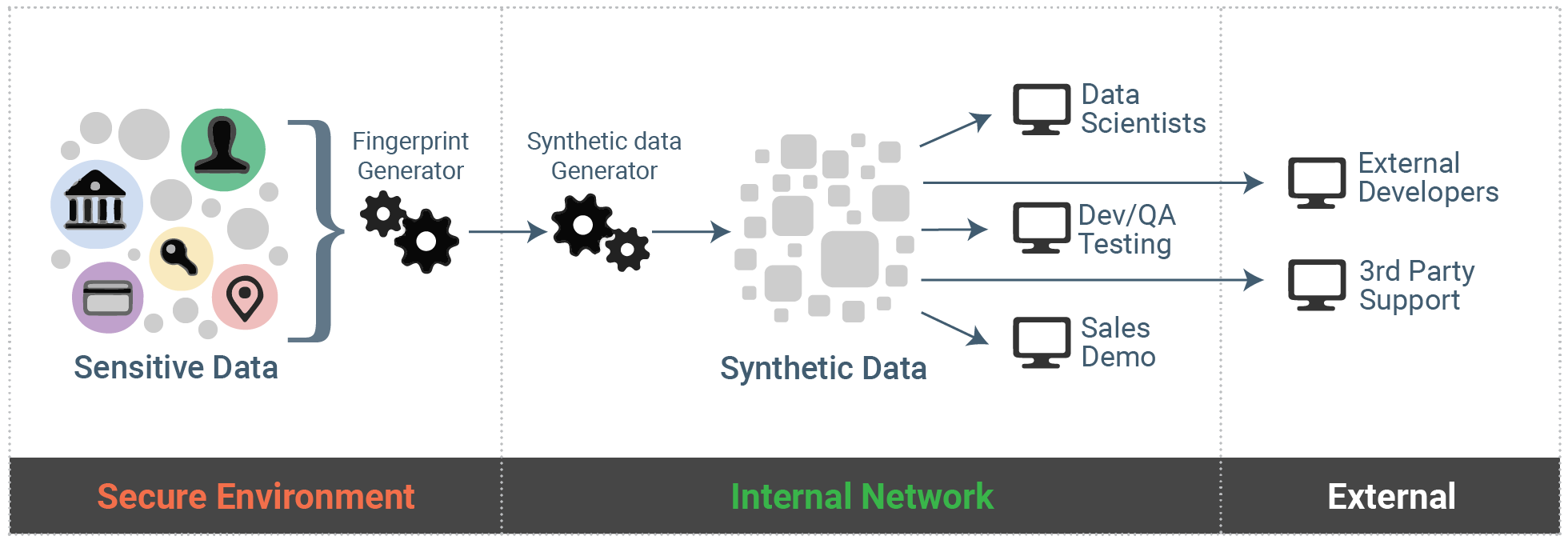
How Tonic helps organizations
The synthetic data generated by Tonic frees organizations to increase access and reduce risk—teams can share their data, protect the business, and simplify their infrastructure.

Questions, comments, feedback? Email us at hello@tonic.ai
Learn more at www.tonic.ai




Make your sensitive data usable for testing and development.

