Stop waiting for data.
Start shipping.
Unblock AI training, development, and testing workflows with safe, realistic synthetic data from your production patterns or from scratch.

App development
Accelerate velocity, unblock teams.
Rapidly generate realistic synthetic data—from scratch or modeled after production—to eliminate data dependencies and ship product innovations faster.

Testing & QA
Secure testing, zero regrets.
Transform sensitive production databases into high-fidelity, referentially intact test data to accelerate release cycles and drastically reduce critical defects escaping to production.

AI model training
Unlock sensitive data, safely.
Detect, redact, and synthesize sensitive data in your unstructured datasets to develop and fine-tune LLM and AI models without compromising privacy.


Reinforcement learning
Simulated worlds, smarter agents.
Train your agents in high-fidelity simulated environments built on synthetic data, personas, tasks, and live APIs that mirror real-world complexity at scale.


Trusted by engineering teams throughout the world
.svg)








.svg)

.svg)
.svg)



.svg)


.svg)


.svg)
.svg)
.svg)


Data synthesis for every stage of development, testing, and AI model training
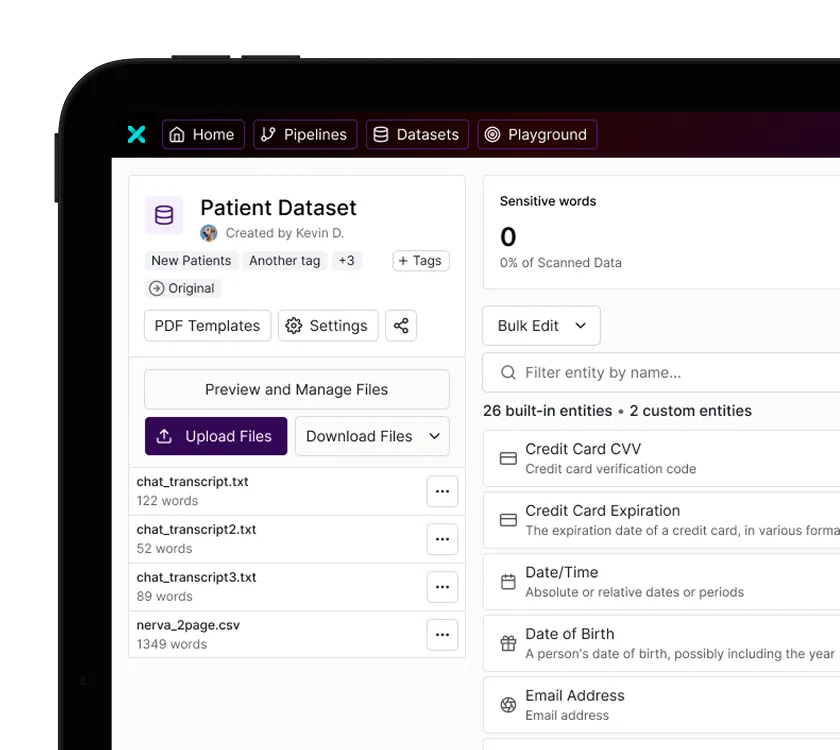
Generate synthetic data from scratch
Turbocharge new product development and AI model training with fully relational synthetic databases, realistic unstructured data, and mock APIs generated at scale and on demand.
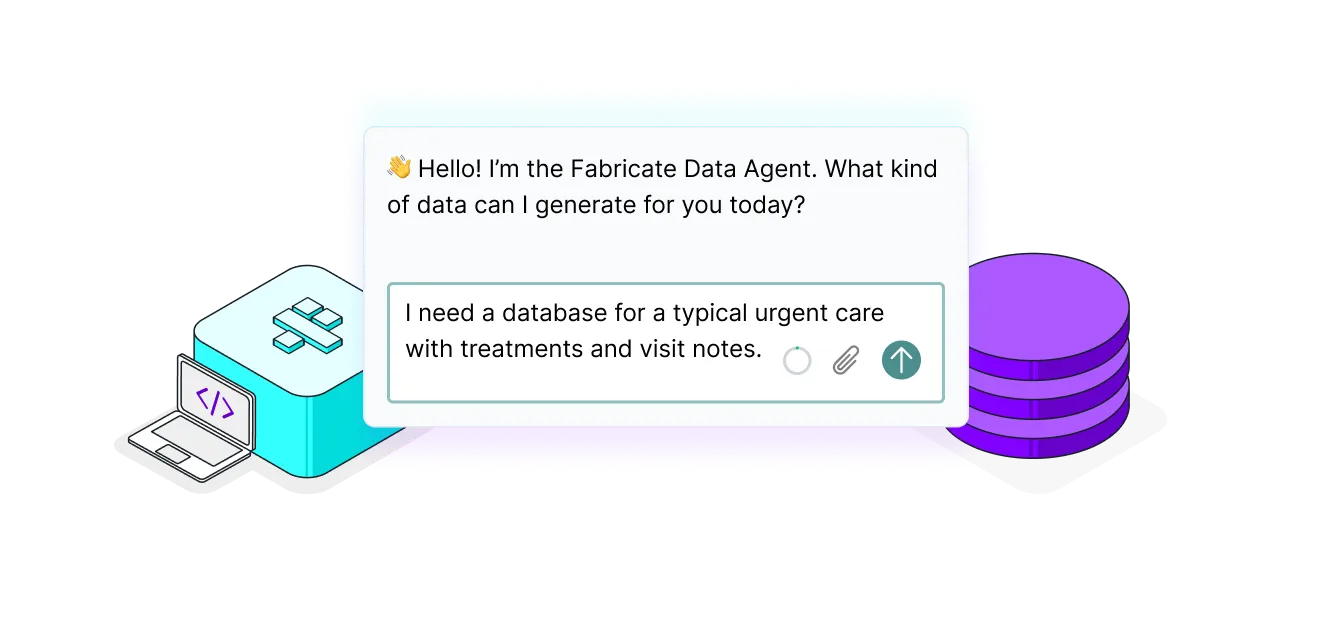
How to generate synthetic data via agentic AI
Read this guide

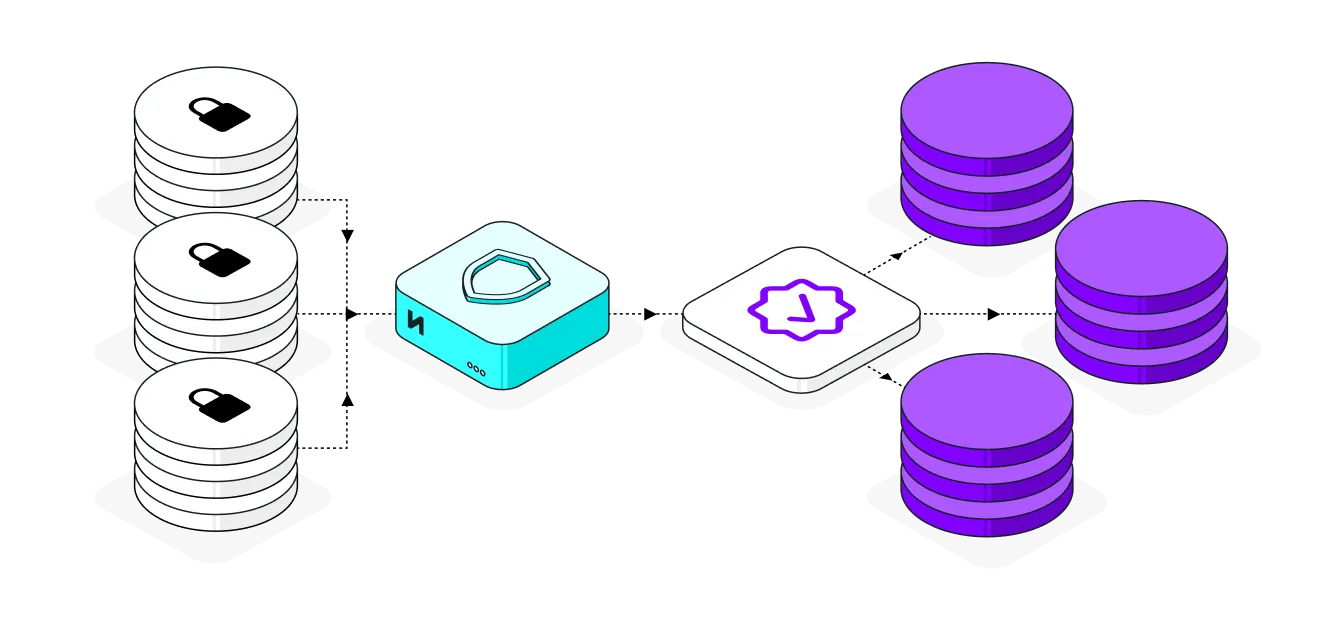
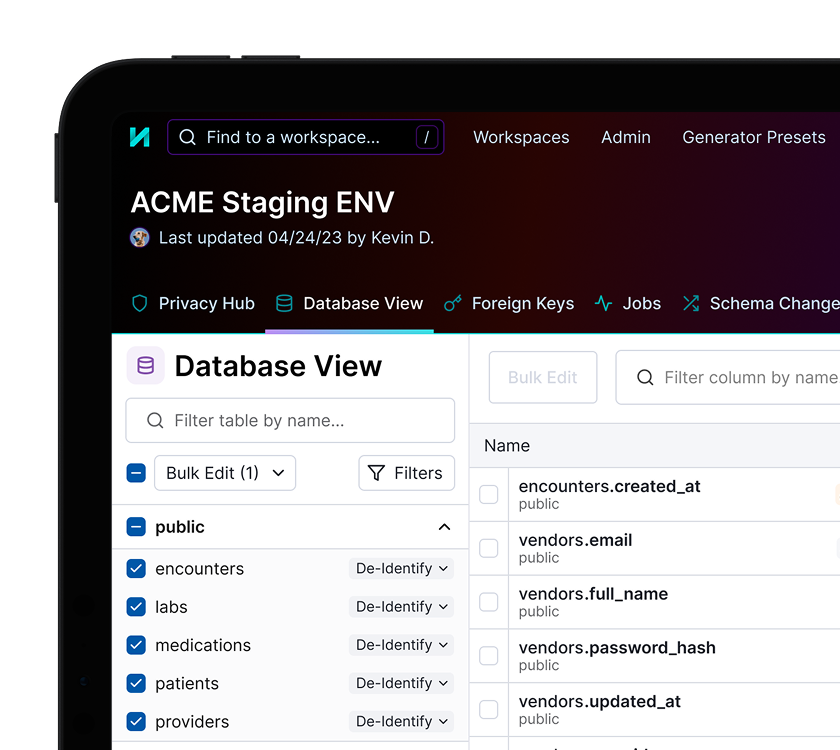
Sanitize production data for testing
Accelerate your release cycles and eliminate critical bugs in production by fueling staging and QA environments with high-fidelity test data that mirrors the complexity of production.

Unlock unstructured data for AI
Safely leverage your unstructured data in AI development while preventing data leaks and ensuring regulatory compliance through industry-leading data redaction and synthesis.
Find the product and plan that works for you.


Deliver the value of AI-powered synthetic data across your organization
Technology tailored for data privacy compliance across regulated industries




Certified, secure solutions to ensure your company’s compliance.
We're proud recipients of glowing reviews from our customers










.svg)






Data synthesis guides
Explore the world of data synthesis and discover how it plays a crucial role in safeguarding sensitive information while maintaining data utility in software and AI development.





Using real-world data for synthetic data generation with the Fabricate Data Agent









.avif)









Uploading and referencing production data in a rule-based dataset, with Tonic Fabricate











.avif)


.avif)

Synthesizing healthcare data for AI model training, with HIPAA Expert Determination


.avif)




Understanding data redaction: Use cases, benefits, and how to automate redaction workflows




.avif)





What is retrieval augmented generation? The benefits of implementing RAG in using LLMs

Using custom models in Tonic Textual to redact sensitive values in free-text files

















Frequently asked questions
Tonic.ai is a synthetic data platform that gives engineering and AI teams on-demand access to safe, realistic data for software development, testing, and AI model training. Instead of waiting on slow data provisioning cycles or risking sensitive data exposure, teams use the Tonic platform to generate, de-identify, and subset both structured and unstructured data at scale.
The platform includes three products: Tonic Fabricate for generating synthetic data from scratch or from existing databases, Tonic Structural for transforming sensitive production data into safe, high-fidelity test data, and Tonic Textual for redacting and synthesizing unstructured data and free-text. Each includes a built-in AI agent that replaces hours of manual configuration with minutes of chat and automated workflows.
Most organizations know they shouldn't use production data in development, testing, or training environments, but many still do because the alternatives are too slow or too unrealistic. Tonic.ai gives teams a way out.
Tonic Structural connects to your production databases, applies automated data masking and de-identification, and provisions high-fidelity test data that preserves schema structure, referential integrity, and business logic. Its patented subsetting engine creates targeted, isolated datasets so teams can work without collisions. When production data isn't available or appropriate, Tonic Fabricate generates logically consistent synthetic data from scratch or modeled on an existing database's structure and distributions. For unstructured data, Tonic Textual detects and redacts sensitive information in free-text, documents, and files.
Yes. Tonic.ai supports AI development across two dimensions: generating net-new training data and safely unlocking the sensitive data your organization already has.
Tonic Fabricate generates realistic structured datasets, unstructured text, and mock APIs on demand, with control over schema, complexity, coverage, and ground truth. Connect an existing database and let Fabricate model its patterns, or build entirely from scratch. Use it for populating reinforcement learning environments, building evaluation datasets, generating labeled data for fine-tuning, and addressing cold-start scenarios where no real-world dataset exists.
Tonic Textual detects, redacts, and synthesizes sensitive information within your existing unstructured data so AI teams can use it for model training and RAG systems without privacy risk. Together, they give AI teams what they need without dependence on scarce, sensitive, or expensive real-world data.
Tonic.ai is built for regulated environments. Healthcare and financial services organizations use the Tonic platform to maintain HIPAA, PCI, GDPR, and SOC 2 compliance across development and AI workflows without bottlenecking engineering teams.
For healthcare, Tonic Structural and Tonic Textual de-identify protected health information (PHI) in both structured databases and unstructured clinical text, with optional HIPAA Expert Determination to validate Safe Harbor compliance. For financial services, Structural masks PCI-regulated fields and Fabricate generates compliant synthetic data that mirrors the complexity of production, so development and testing proceed without exposing real customer records.
Each product addresses a different data challenge, and for many organizations, they work together:
Tonic Fabricate generates synthetic data from scratch or modeled on an existing database. Use it for new product development, AI model training, demo environments, load testing, mock APIs, or any scenario where production data doesn't exist or isn't suitable.
Tonic Structural transforms existing production data into safe, high-fidelity test data. Use it when testing and QA depend on data that mirrors production's complexity, with sensitive fields masked and referential integrity preserved.
Tonic Textual redacts and synthesizes sensitive information in unstructured data: free-text, documents, PDFs, and files. Use it when AI or compliance initiatives involve text-based data containing PII, PHI, or proprietary information.
Testing can't keep up with development when data is a ticket. Engineers wait on cross-team requests, fight over shared staging environments, and waste time scripting mock data or troubleshooting broken test suites caused by stale, unrealistic data.
Tonic Structural gives teams self-service access to high-fidelity test data with automated masking and subsetting, and schema changes sync automatically. Tonic Fabricate lets teams generate data for new features, parallel development, and load testing, without waiting on anyone. Both products include built-in AI agents that turn hours of manual configuration into a guided, conversational workflow, resulting in faster release cycles, fewer escaped defects, and engineers freed from low-value data sourcing.
Yes. Organizations frequently adopt the Tonic platform to modernize away from legacy TDM tools like Informatica TDM, Delphix, or IBM Optim, as well as homegrown scripts that don't scale.
Legacy solutions tend to be slow to refresh, brittle when schemas change, and expensive to maintain. Tonic Structural offers a modern alternative: AI-powered configuration, native connectors, automated masking that preserves referential integrity, and a patented subsetter for targeted provisioning. And where legacy tools focus narrowly on structured database masking, Tonic.ai extends coverage to unstructured data (via Textual) and net-new data generation (via Fabricate), including model training data, mock APIs, and demo environments.

