
.svg)








.svg)

.svg)
.svg)



.svg)


.svg)


.svg)
.svg)
.svg)


👋 Say goodbye to brittle scripts and outdated tools.
With an intuitive UI, fully accessible API, and native data connectors, Tonic Structural is the test data management solution built for today’s data environments.
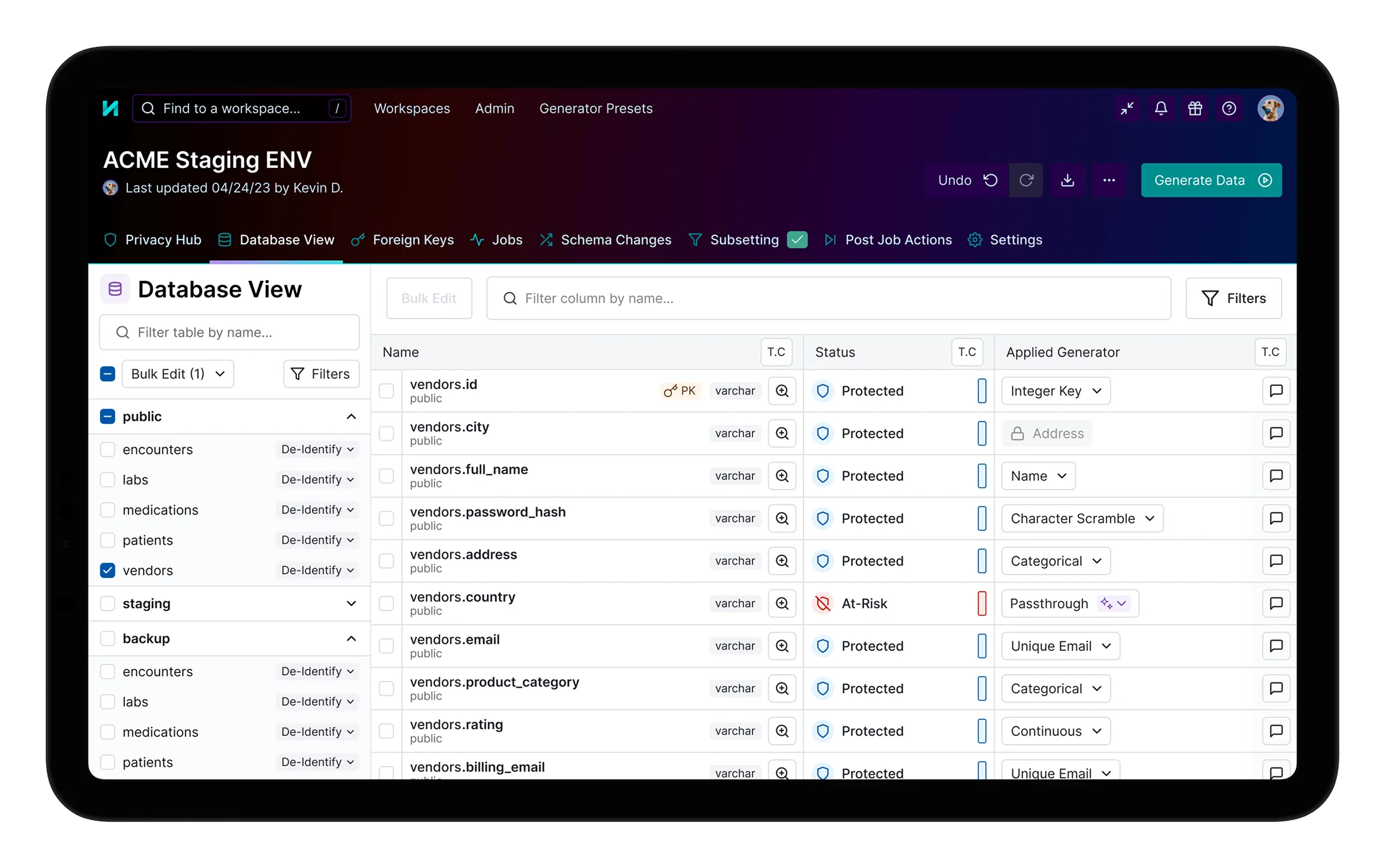
Automated sensitive data discovery
Automatically detect PII and PHI throughout your data, configure custom rules to catch sensitive data types unique to your organization, and bulk-apply compliant, recommended generators.
Consistent data masking and synthesis
Capture your data’s complexity with ease through automated, consistent transformations that preserve relationships and referential integrity across testing and development environments.

Patented database subsetting
Create targeted, coherent data subsets for local development and debugging that are orders of magnitude smaller than full production copies without breaking referential integrity.

TDM without the tedium
Automate data de-identification with agentic AI: leverage the built-in agent to apply and configure generators, populate custom data types, and enforce data compliance requirements.
Enterprise-grade security and collaboration
Leverage secure collaboration features, including role-based access control, workspace sharing, privacy reports, and audit trails to ensure data governance across your organization.

Rapid data refresh
Automatically detect and address schema changes, and schedule regular data generations to eliminate bugs and test suite failures tied to stale test data and out-of-sync environments.

Generate compliant test data that looks, acts, and feels just like production.
Deploy Tonic Structural
Deploy a self-hosted instance of Structural, or work with your data in our Cloud offering.

Connect to your data
Structural offers native connectors to all the leading relational and NoSQL databases, data warehouses, lakehouses, and file types.
Transform your data
Automatically detect sensitive data types and realistically mask or synthesize new values that maintain consistency and preserve relationships across your database.
Provision realistic data on demand
Spin up isolated, fully hydrated databases as often as you need, to ensure each developer is equipped with compliant, targeted test data.
Performant native data connectors
Seamlessly integrate with modern and traditional data sources, including relational databases, data warehouses, flat files, and NoSQL data stores, maintaining consistency in transformations across environments and database types.













Full-spectrum data synthesis with the Tonic.ai product suite
Get consistent and complete coverage for your data de-identification needs by pairing Tonic Structural’s relational data capabilities with Tonic Textual’s unstructured data redaction and synthesis. Add Tonic Fabricate for synthetic data generated from scratch, to fill the gaps where existing data is lacking. Tonic.ai’s solutions ensure data utility and compliance across testing, development, and AI model training.
Data synthesis guides
Explore the world of data synthesis and discover how it plays a crucial role in safeguarding sensitive information while maintaining data utility in software and AI development.










Frequently asked questions
Tonic Structural is a data de-identification platform designed to protect sensitive structured and semi-structured data while preserving schema accuracy and data usability. It applies advanced, secure transformations directly to existing datasets rather than generating entirely new records.
Tonic Structural is widely used in highly regulated industries like finance, insurance, and healthcare where strict privacy controls are required but data realism is key for software development and testing.
Tonic Structural integrates into CI/CD pipelines and data governance programs, enabling repeatable, policy-driven data protection that scales across teams and environments.
Yes. Tonic Structural maintains primary and foreign key relationships across complex schemas, ensuring applications and tests behave as expected after data is de-identified.
Teams should use Tonic Structural when they need to maintain the intricate business logic and referential integrity of their existing production data. Structural’s high-fidelity approach ensures that teams can catch complex, real-world edge cases and troubleshoot production-level issues with datasets that are firmly representative of actual user behavior.
Tonic Structural uses configurable techniques such as masking, tokenization, generalization, scrambling, and format-preserving encryption. These transformations ensure sensitive fields are protected while maintaining realistic formats, relationships, and constraints required for downstream systems.

