Data redaction is the process of identifying and replacing sensitive values in text. This process is intended to ensure both data privacy and data security, which also helps ensure compliance with security and privacy regulations. It allows you to use text data for purposes such as tests, demos, and LLM model training.
For example, you might have transcripts of customer calls or PDFs of loan applications. Because they contain sensitive values such as names, identifiers, and other information that you cannot expose, you can't use this content without first replacing those values.
Redaction processes ensure secure collaboration, mitigate the risks of access by unauthorized users, and help create a culture of compliance and trust. In this article, we will look at what data redaction is, how to implement it, and its critical role in building a stronger security framework for your data. We'll also show how Tonic Textual fits into an automated redaction process.
What is data redaction?
Data redaction is used to protect Personally Identifiable Information (PII), Protected Health Information (PHI), financial details, or other confidential data by removing or obscuring sensitive information within a document or dataset to prevent unauthorized access or exposure.
Data redaction is different from other common data protection strategies such as encryption or data masking, which uses a decryption key to conceal real data. Instead, data redaction provides a powerful tool that first breaks data down into separate pieces of information and then permanently removes the parts of a document or dataset that could expose sensitive data.
For industries like healthcare, finance, and legal services––where stringent privacy regulations such as GDPR, HIPAA, and CCPA mandate strict control over sensitive data––data redaction plays a vital role in a proactive security strategy. Redaction allows organizations to maintain the usability of non-sensitive data while ensuring that private information remains concealed.
For example, in legal documents, client details like their name or email address may be blacked out or replaced with placeholders to ensure their confidentiality. Similarly, any field containing private data can be categorically redacted across the data set, such as the last four digits of a Social Security number.
By erasing or obscuring sensitive details, redacted data also helps protect against potential data breaches and insider threats. Limiting access to sensitive data in this way makes sure that only necessary information is visible to authorized personnel, even in a secure environment. And, by integrating automated reduction tools and workflows, organizations can reduce human error and strengthen broader security protocols.
Use cases for data redaction
From AI development and machine learning (ML) model training to Large Language Model (LLM) implementation, data redaction helps organizations and businesses across industries ensure that sensitive details are not exposed during data processing. Below are five use cases that demonstrate some of the many practical applications of data redaction.
AI development in healthcare
LLM solutions in healthcare frequently rely on sensitive documents, including patient records, to enhance diagnostic accuracy and optimize treatment plans. Since these records contain PII and PHI, redaction can remove those details before feeding the data into AI workflows, allowing developers to safely use anonymized data when developing LLMs.
Learn more: Data privacy in healthcare.
LLM training in finance
For financial institutions, LLMs are being used to detect fraud or assess credit risk––but this requires training the models with sensitive financial details that could be put to nefarious purposes by unauthorized users if the data is exposed via the LLM. Redacting sensitive client details––names, credit card numbers, and addresses, for example––ensures compliance with regulations such as CCPA while still allowing the model to learn patterns and make accurate predictions based on anonymized transaction data.
LLM implementation for customer support
Any organization using LLMs as customer service tools, including chatbots, needs to redact private data from their training datasets. For example, a financial services chatbot has to be able to access specific transactional details for the sake of context but can't risk exposing the associated data. Redaction allows the chatbot to be trained properly without worrying about data exposure.
Regulatory compliance in legal services
In the case of legal AI tools––such as contract analysis platforms or case management systems–– LLMs process large volumes of text, which includes sensitive client details. Before these documents can be used in AI or LLM workflows, confidential information such as client names, addresses, or case specifics must be redacted to ensure compliance with privacy laws like GDPR and CCPA.
Key benefits of data redaction
Data redaction provides robust data protection for privacy and compliance purposes, making it an essential tool for maintaining a proactive security culture. By either removing or obscuring confidential data, redaction maintains information security while keeping non-sensitive content usable. Let's look at several of the key benefits of redacted data in more depth.
Strengthened data privacy
Data redaction ensures that personal details such as PII and PHI are protected from unauthorized access or exposure. This proactive approach significantly reduces the risk of data breaches, safeguarding individual privacy and protecting organizational reputation.
Regulatory compliance
Data redaction enables businesses to meet the strict requirements of data privacy regulations like GDPR, HIPAA, and CCPA while securely using and sharing data for operational needs.
Mitigating insider threats
Redacting sensitive data reduces the potential for misuse by unauthorized users who might gain access to confidential information. So even if internal security requirements are compromised, the most critical data will remain protected from exposure.
Supporting data sharing and collaboration
In industries like healthcare and finance, it is often necessary to share data for research or analysis purposes. Data redaction allows organizations to collaborate securely, providing valuable insights while preventing the sharing (and potential compromise) of sensitive or identifiable information.
What type of data needs to be redacted?
The type of data that requires redaction typically includes categories that are either regulated by privacy laws or deemed mission-critical by organizations. Below are five data types that can benefit the most from data redaction methods.
Personally Identifiable Information (PII)
PII includes data points such as names, Social Security numbers, physical or email addresses, and other contact details that can be used to uniquely identify an individual. Redacting PII can be critical for protecting privacy and complying with regulations like GDPR and CCPA, especially during data sharing or processing.
Protected Health Information (PHI)
PHI consists of medical records, insurance details, and health-related identifiers, including patient names and dates of service. In the healthcare sector, redacting PHI can be an effective approach to compliance with HIPAA while enabling the safe use of medical datasets for research and analysis.
Financial information
Sensitive financial data, such as credit card details, bank account details, or transaction histories, must be redacted to prevent fraud and identity theft. This is particularly important in industries like banking, e-commerce, and insurance.
Proprietary business information
This includes trade secrets, intellectual property, and internal communications sensitive to a specific organization. Redacting proprietary data ensures confidentiality during audits, mergers, or external collaborations.
Employee records
Employee data, such as salary details, performance reviews, or disciplinary actions, often contains private information. Redacting sensitive elements protects employee privacy and minimizes risks during internal reviews or external audits.
Safely redact your data for AI model training.
Unblock your AI initiatives and build features faster by securely leveraging your free-text data.
Understanding how data redaction works
The data redaction process usually begins by detecting specific data points––for example, names, addresses, or financial details––via pattern recognition or advanced techniques like Named Entity Recognition (NER). Once identified, these data points are either blacked out or replaced with meaningless placeholders.
In free-text data, automatic redaction solutions can scan unstructured text to automatically detect and redact PII and PHI. This ensures that even complex datasets, including JSON formats, can be securely shared or processed without the risk of revealing sensitive information.
Organizations must also consider whether a "build" or "buy" approach is best for their data redaction needs. Companies must weigh the time, cost, and expertise required to develop an in-house tool against the reliability, scalability, and compliance benefits of ready-made solutions like Tonic Textual.
Automating data redaction
With automated data redaction, the file selection, entity detection, entity redaction and synthesis, and redacted file creation are built into an automated process.
For example, a PDF of every processed loan application is added to a repository. You want to make sure that all of these applications are scanned and redacted, so that you can safely use them in other systems.
You can set up an automated process that regularly checks for new files in the repository. Every time a new document is added, the system automatically sends the document for entity detection and redaction. The redacted document is added to a different repository where it is available to use for testing and training.

Automated data redaction with Tonic Textual
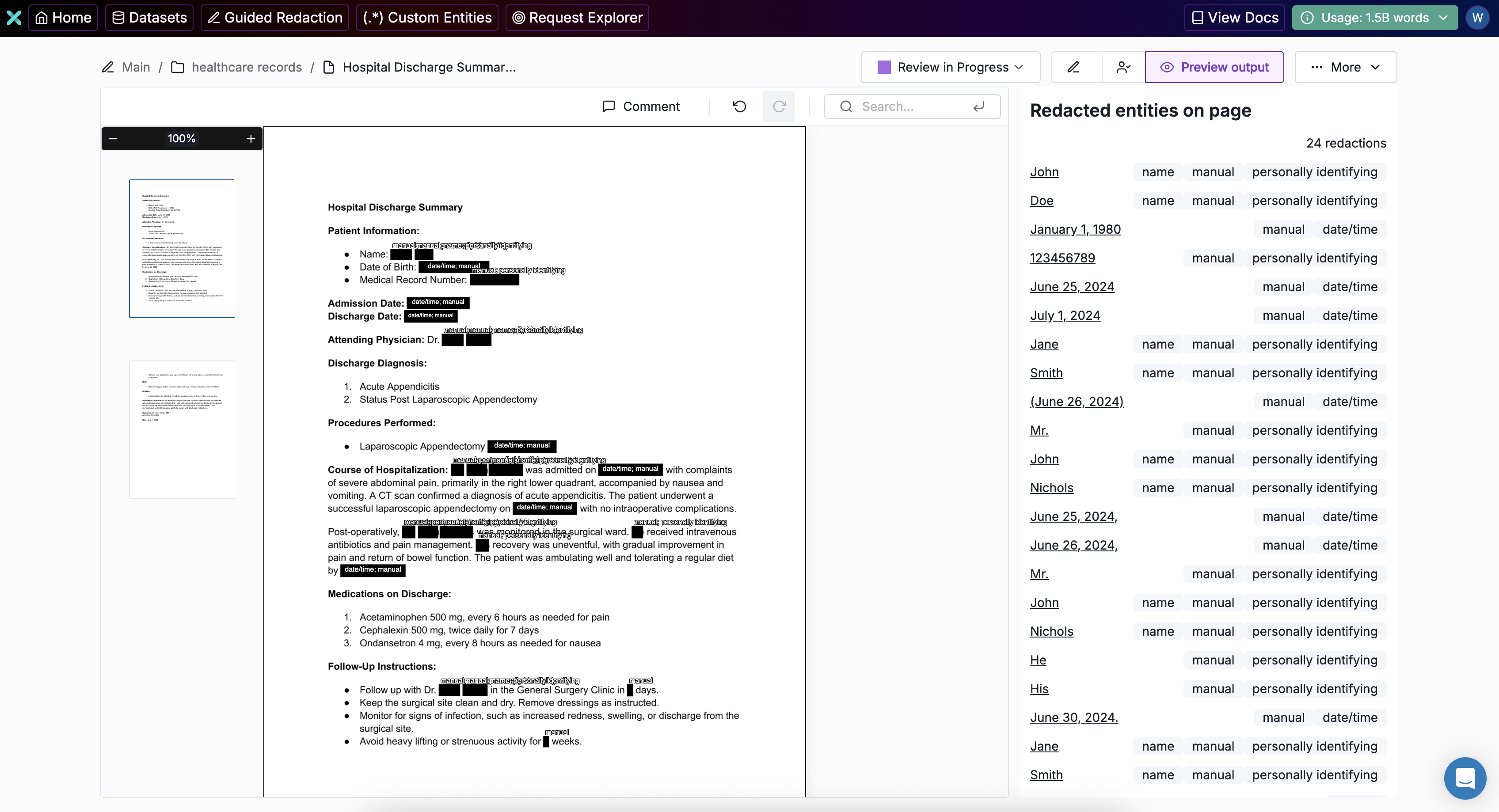
Tonic Textual offers a robust suite of capabilities to support data redaction and synthesis of free-text and image files. Textual automatically identifies sensitive values (aka entities) and produces replica files that replace the detected values with redacted or synthesized values, while preserving formatting and document type.
Named entity recognition and value synthesis
To identify sensitive entities, Textual uses a set of Named Entity Recognition (NER) models and gives users the choice to redact values deemed sensitive, or replace them with synthetic alternatives that preserve context. For example in a financial document, “Steve Watson” may be replaced with “George Schmidt” and account numbers and social security numbers will be replaced with new values that preserve the original structure.
If pure redaction is preferred,Textual replaces the detected entities with tokenized categorical values (for example, replaces John with NAME_GIVEN and (415) 555-555 becomes PHONE_NUMBER).
Custom data models
Textual’s detection capabilities start with a broad library of built-in NER models, but many organizations have domain-specific sensitive values that off-the-shelf models cannot reliably detect. With self-serve Custom Entity Types, teams can define, annotate, train, and deploy their own entity detection models directly within Textual without requiring data science expertise. This makes it possible to accurately detect proprietary identifiers, industry-specific terminology, and internal data formats that are critical to your workflows.
Human-in-the-loop workflows
Automated entity detection is powerful, but certain use cases require strict human oversight to ensure absolute protection of sensitive data; especially when documents might contain classified information or trade secrets.
Guided Redaction in Tonic Textual introduces a human-in-the-loop workflow that allows teams to review, validate, and refine redaction decisions before data is finalized. Users can inspect detected entities in context, confirm or reject automatic redactions, and manually mark additional sensitive values that require protection.
By combining automated NER with guided human review, Textual gives teams confidence that sensitive data is consistently protected while maintaining speed and scalability. The result is a practical balance between automation and control, ensuring de-identified data is both safe and usable for downstream AI, analytics, and sharing workflows.
Textual advantages over conventional methods
Without Tonic Textual, teams often rely on a patchwork of open-source tools, custom models, and manual review to redact sensitive data. These approaches are difficult to maintain, slow to scale, and require significant ongoing engineering and analyst effort.
Textual delivers more accurate models, broader entity coverage, faster inference, and enterprise-grade support out of the box. Guided Redaction further reduces hours of manual redaction by focusing human review only where it matters, enabling teams to move faster while maintaining confidence in the quality and consistency of their de-identified data.
Data redaction vs data masking: What is the difference?
Data redaction and data masking are both used to safeguard sensitive information when testing software or training LLMs, but they serve different purposes and are applied in different ways. While redaction focuses on permanently removing or obscuring confidential data, masking retains the underlying structure, meaning, and relationships by substituting sensitive details with realistic but artificial values. Let's discuss the key differences between these two approaches.
Permanence vs substitution
Data redaction either removes or obscures sensitive data permanently, rendering it inaccessible. In contrast, data masking replaces sensitive details with synthetic but realistic substitutes, helping to preserve the dataset's usability for testing or analytics without risking real data.
Use cases
Typically, redacted data is used in scenarios that require stricter privacy, such as legal document sharing or healthcare record distribution, where sensitive information must be removed entirely. Masking, on the other hand, is often applied in development or testing environments to simulate real-world data without risking a privacy breach.
Data utility
Redaction, while guaranteeing confidentiality for sensitive data by eliminating it from the dataset, can also reduce that dataset's utility. Masking, however, keeps the data's original structure and usability, enabling effective testing and development while protecting private information.
Regulatory compliance
Both redaction and masking support compliance with relevant regulations like GDPR and HIPAA, but redaction is especially appropriate for meeting requirements where data cannot be retained, while masking works better in scenarios that prioritize data usability.
How Tonic.ai's solutions can help
Tonic.ai offers all the capabilities you need to address your data redaction use cases across both structured and unstructured data. For structured data, Tonic Structural offers multiple redaction methods among its library of generators, enabling the generation of realistic, de-identified datasets that maintain usability.
For unstructured text data, Tonic Textual employs advanced Named Entity Recognition (NER) to detect and redact sensitive information while preserving context for model training. Likewise, when redaction efforts require manual approval by different groups and strict audit trails, Guided Redaction equips teams with human oversight combined with automation to ensure that teams can move quickly and with confidence.
Data redaction is a necessity for any data privacy strategy. From protecting PII and PHI for AI development to embedding automated redaction into your document sharing strategy, effective data redaction strategies help businesses minimize risks while maximizing data usability.
Redaction platforms like Tonic.ai’s solutions streamline the process of generating redacted data, ensuring secure, efficient, compliant workflows across structured, semi-structured, and unstructured data. Take the next step in securing your data––connect with our team today.




